

DeepSeek算力需求暴降,为什么全球算力竞赛反而更疯狂了?
春节期间,国产大模型DeepSeek-R1的横空出世,一度让人们看到了“降本增效”的曙光。DeepSeek-R1以更低的成本和算力需求,实现了世界一流的模型性能,打破了大模型领域“烧钱买芯片”的传统路径。
彼时彼刻,英伟达股价应声下跌,似乎印证了市场对算力需求放缓的预期,也宣告着“暴力堆算力”时代的终结。
然而,在通往AGI的征途上,算力真的不再重要了吗?至少,从硅谷科技巨头们的行动来看,答案是否定的——这场效率革命,正在将人类拽入更疯狂的算力竞赛。
一、 巨头加码:硅谷的“反效率”投资
与DeepSeek的算力焦虑不同,硅谷的科技巨头们显然没有对此产生任何遏制的担忧,反而在不断增加投入。1月底以来,谷歌、微软、Meta和亚马逊这四大科技巨头相继发布了最新财报。令人瞩目的是,他们不约而同地在财报中强调:2025年将加大在算力方面的投入。
谷歌母公司Alphabet在2025年的资本开支目标为750亿美元,较上年激增42%。微软同样表示,2025财年将在人工智能数据中心上投资800亿美元,并透露其对于算力投资的节奏保持谨慎,原因在于硬件的快速迭代。
Meta和亚马逊也分别在财报中披露了大幅增加算力投入的计划。Meta将其资本开支预算增加了66%,而亚马逊则计划在2025年投入1000亿~1050亿美元,主要用于AI和云服务领域。
面对DeepSeek,硅谷的四大科技巨头——谷歌、微软、Meta和亚马逊,以加码算力的方式回应了这一挑战。算力,似乎仍然是支撑未来AI技术发展的核心资源。
二、 杰文斯悖论在AI领域的再度应验
四巨头在算力上的持续投入,并非对DeepSeek视而不见。但亚马逊CEO Andy Jassy指出,推理成本的降低并不意味着总支出下降,“我们在云计算领域经历过类似情形”。微软CEO纳德拉则在社交媒体上引用了“杰文斯悖论”来表达他的观点。
如经济学家杰文斯所言:技术进步虽然提高了资源的使用效率,但需求的增加常常会导致总消耗量反而增加。
具体到实际,我们可以看到,过去在汽车领域,发动机热效率的提高使得车辆燃油消耗降低,但因使用成本降低,车主反而选择更多购车,最终导致石油的消耗量反而增加。
这一悖论同样适用于AI领域。当微软CEO纳德拉在X平台转发“杰文斯悖论”词条时,现实中正在上演着现代版的技术寓言:1850年,英国蒸汽机的热效率提升了三倍,煤炭消耗量却暴涨了十倍;而今天的R1模型将推理成本压缩了97%,全球的算力需求却因其高性价比反而呈现指数级膨胀。
更残酷的现实在于:DeepSeek-V3的混合专家架构(MoE)在推理环节,需要同时激活14个专家模块。这导致在线服务时,每个token生成需消耗0.78TFLOPs算力,较传统架构高出18%。
可以说,效率革命的B面,是更复杂的资源调度噩梦。
具体到实际数据,可以看到,DeepSeek API调用量在推出后迅速飙升。根据市场机构估算,DeepSeek每秒的推理算力需求已经接近1.6×10^19 TOPs。
而前不久,DeepSeek官方甚至发表声明,暂停其API充值服务,原因便是服务器算力资源紧张。

一系列数据的背后仍然依赖于强大的硬件支持。而DeepSeek的出现,没有抑制算力的需求,反而推动了更多企业和开发者投入更多资源以获得服务,加剧了算力资源的压力。
三、 DeepSeek的隐忧:算力之下的挑战
“成本创新”并不等于“削减算力”。DeepSeek-R1的训练成本大幅降低,但依然遵循着Scaling Law。在其之下,模型性能与算力需求可以近似看作一个正相关函数。过往的模型效率较低,性能提升缓慢;DeepSeek效率较高,性能提升更快。在这种情况下,企业大概率会因为效率更高而加大投入,而非减少投入。
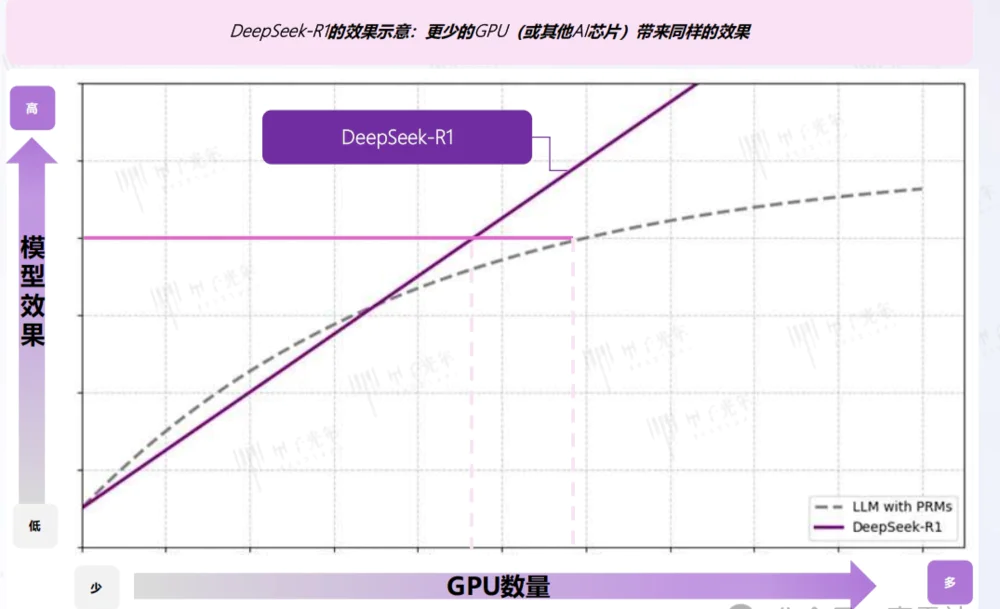
而DeepSeek在算力方面的努力远未结束。随着硬件和算法的不断进化,DeepSeek依然会通过创新优化降低算力需求,但从当前的趋势来看,算力的需求依旧高涨。
与其担心算力过剩,我们或许更应该关注的是:当算力和效率都得到提升时,优质训练数据是否会成为新的瓶颈?
微软研究院的最新模拟显示,要保持大模型性能的指数增长,2026年需要430艾字节(EB)的高质量训练数据——这相当于把人类现存所有文字资料复制2300遍。
为便于理解,依然以汽车为例,当汽车油耗(模型效率)和汽油(算力)都充足时,如果道路(优质训练数据)不足,就会导致“堵车”,出行速度无法进一步提升。
当科技巨头们开始不计代价地购入算力,优质数据的焦虑,正在变异为更本质的危机。
四、产业变局: 本地部署的浪潮
DeepSeek暂停API充值服务,引发了用户对其算力资源的担忧,但在另一方面也意外激活了本地部署的第二战场。
微软率先宣布将针对NPU优化的DeepSeek R1版本直接嵌入Windows 11 Copilot+ PC,让开发者可在本地构建AI应用。英特尔则表示其Ultra系列处理器已实现R1-7B蒸馏模型的本地推理,延迟控制在300ms以内。而国内厂商中,华为、轨迹流动、阿里、知乎等互联网公司也相继宣布部署DeepSeek模型。
甚至,腾讯“元宝”与百度“文小言”也官宣将接入DeepSeek-R1模型。
DeepSeek无疑为LLM大模型的发展提供了新的思路,但这无法从根本上消除全球范围内的算力焦虑。而这场静默的本地部署与算力之争,亦将持续下去。
写在最后:算力竞赛,远未结束
DeepSee-R1的出现,证明了算法优化和工程创新的重要性,也让我们看到了“轻量级颠覆”的可能性。
然而,DeepSeek并不能终结算力竞赛。相反,算力依然是核心驱动力。但这场竞赛将不再是单纯的“堆料”,而是算法与算力的双重博弈。谁能更好地平衡效率与投入,谁就能在这场竞赛中占据优势。
在这场没有终点的马拉松里,DeepSeek既是破局者也是催化剂。它用算法利刃劈开算力铁幕,却释放出更汹涌的欲望洪流……
本文来自微信公众号:观弈行研,作者:我是叁叁啊
